Real-time Accident Anticipation for Autonomous Driving Through Monocular Depth-Enhanced 3D Modeling
Haicheng Liao*, Yongkang Li*, Zhenning Li, Zilin Bian, Jaeyoung Lee, Zhiyong Cui, Guohui Zhang and Chengzhong Xu
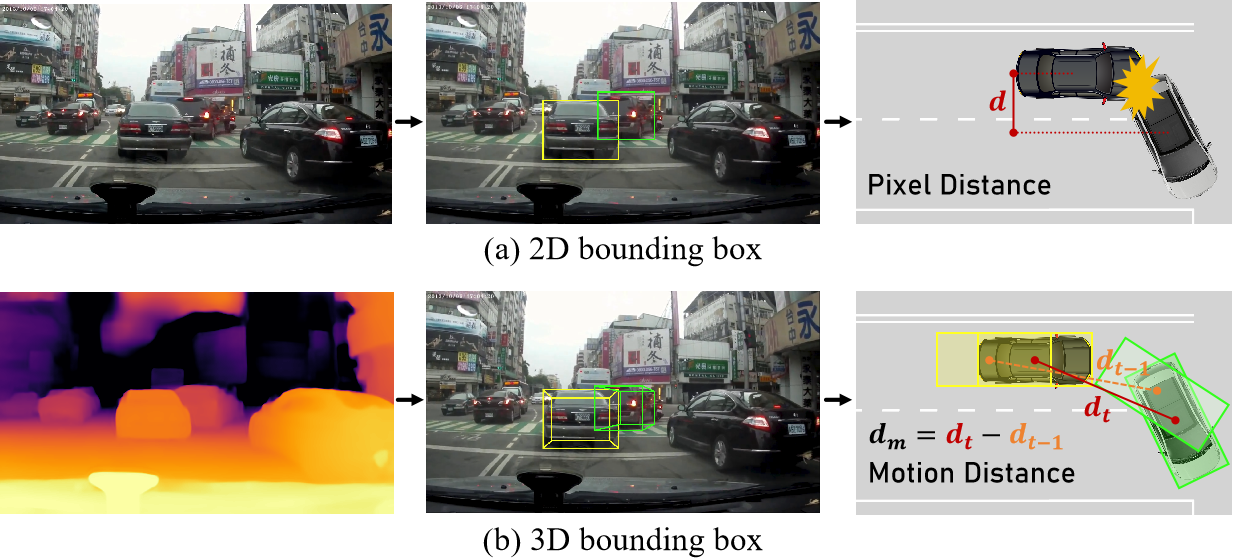
The primary goal of traffic accident anticipation is to foresee potential accidents in real time using dashcam videos, a task that is pivotal for enhancing the safety and reliability of autonomous driving technologies. In this study, we introduce an innovative framework, AccNet, which significantly advances the prediction capabilities beyond the current state-of-the-art 2D-based methods by incorporating monocular depth cues for sophisticated 3D scene modeling. Addressing the prevalent challenge of skewed data distribution in traffic accident datasets, we propose the Binary Adaptive Loss for Early Anticipation (BA-LEA). This novel loss function, together with a multi-task learning strategy, shifts the focus of the predictive model towards the critical moments preceding an accident. We rigorously evaluate the performance of our framework on three benchmark datasets—Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), AnAn Accident Detection (A3D), and DADA-2000 Dataset—demonstrating its superior predictive accuracy through key metrics such as Average Precision (AP) and mean Time-To-Accident (mTTA).
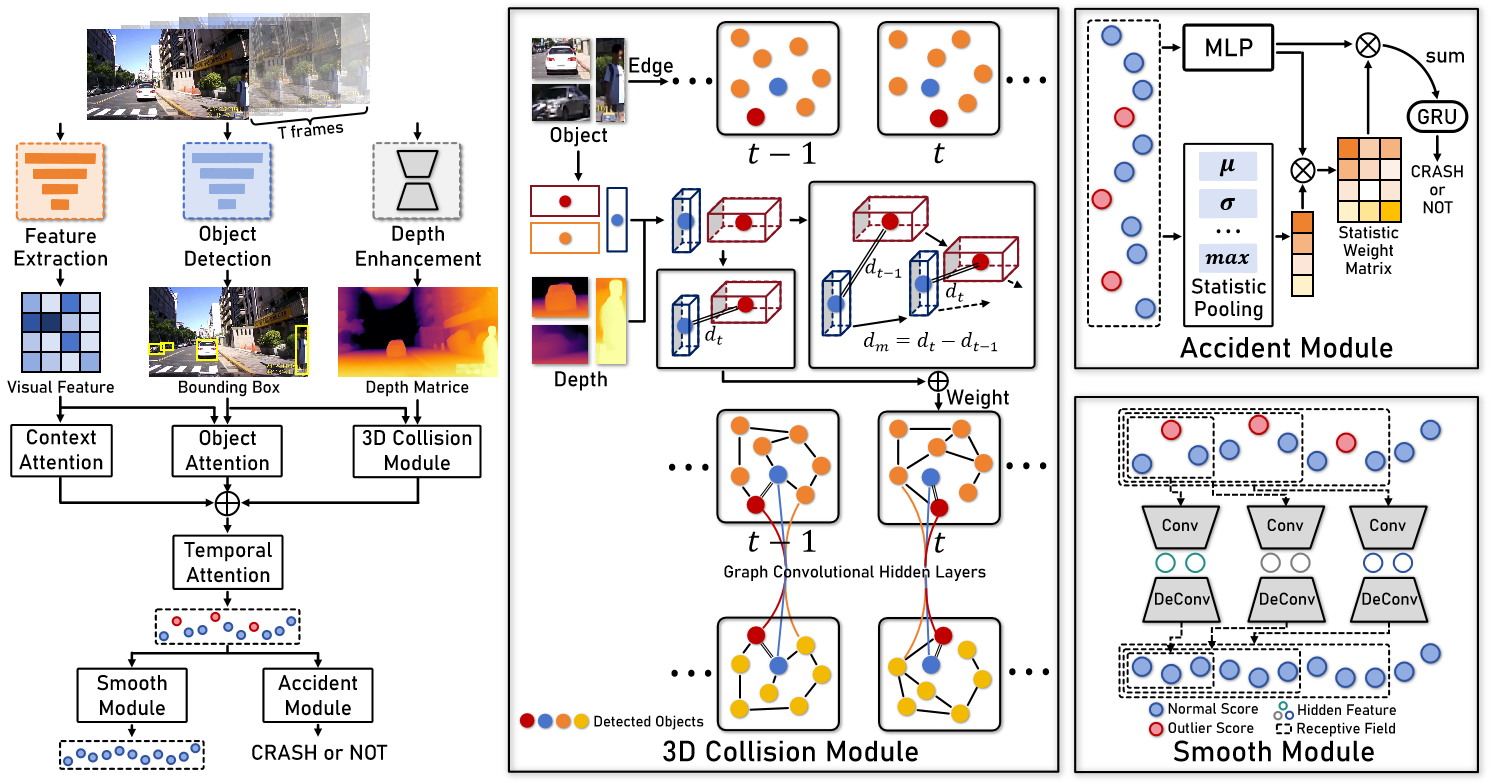
Overview of the Model Structure:
1. Monocular Depth-Enhanced 3D Modeling: Traditional models often rely on 2D pixel distances, which can miss crucial spatial dynamics in traffic scenes. AccNet overcomes this by using monocular depth estimation to extract precise 3D coordinates of traffic participants (like vehicles and pedestrians). This allows for a more accurate depiction of real-world distances and interactions between objects, which is critical for predicting accidents. The model uses the ZoeDepth algorithm to enhance depth perception from dashcam videos. By calculating the 3D positions of objects in each frame, AccNet improves the ability to detect potential collisions by understanding the scene in three dimensions rather than just two.
2. Context and Object Attention Mechanisms:
3. 3D Collision Module: This module calculates the real-world distances between objects based on their 3D coordinates, which are derived from the depth-enhanced modeling. It then constructs a graph representing the spatial relationships between these objects, allowing the model to better understand potential collision scenarios. By focusing on the actual 3D spatial dynamics, the 3D Collision Module provides a more reliable basis for predicting accidents compared to traditional methods that rely on 2D pixel measurements. Combined with a multi-task learning strategy, BA-LEA ensures that the model learns to prioritize accident prediction while maintaining stability and generalizability across various driving scenarios.
4. Monocular Depth-Enhanced 3D Modeling: This novel loss function is designed to address the data imbalance issue common in accident prediction tasks, where non-accident scenarios dominate the data. BA-LEA shifts the model's focus toward critical pre-accident moments, improving its ability to predict accidents early and accurately.
Our experiments on the DAD, CCD, and A3D datasets demonstrate the exceptional performance of our model on all three datasets. These evaluation results indicate an inverse relationship between AP and mTTA, suggesting that a higher AP typically results in a shorter mTTA. The presented results demonstrate a balance between the two metrics, indicating that our model achieved the highest AP values across the datasets, outperforming the second-best by 2.6% on the DAD dataset. AccNet also surpasses every other model in terms of mTTA. Notably, UString is significantly outperformed by our model in AP by 7.1% on DAD and 1.9% on A3D, demonstrating superior overall performance. To demonstrate the superiority of our model, we compared the best AP among the models. Since there were only small differences between the models on the CCD and A3D datasets, we primarily focused on the DAD dataset. AccNet achieved the highest AP value, along with the corresponding highest mTTA. Moreover, our model achieved the highest AUC, indicating that it not only effectively distinguishes accident videos but also ensures the highest accuracy. However, it is important to note that our TTA@80 and TTA@50 performance are slightly lower than that of DSTA, indicating that our model takes a more cautious approach in identifying the majority of positive samples. Notably, as comparing the best mTTA without considering AP does not provide meaningful insights, such a comparison is not included in our analysis.