When, Where, and What? A Benchmark for Accident Anticipation and Localization with Large Language Models.
Haicheng Liao*, Yongkang Li*, Chengyue Wang, Yanchen Guan, KaHou Tam, Chunlin Tian, Li Li, Chengzhong Xu, Zhenning Li
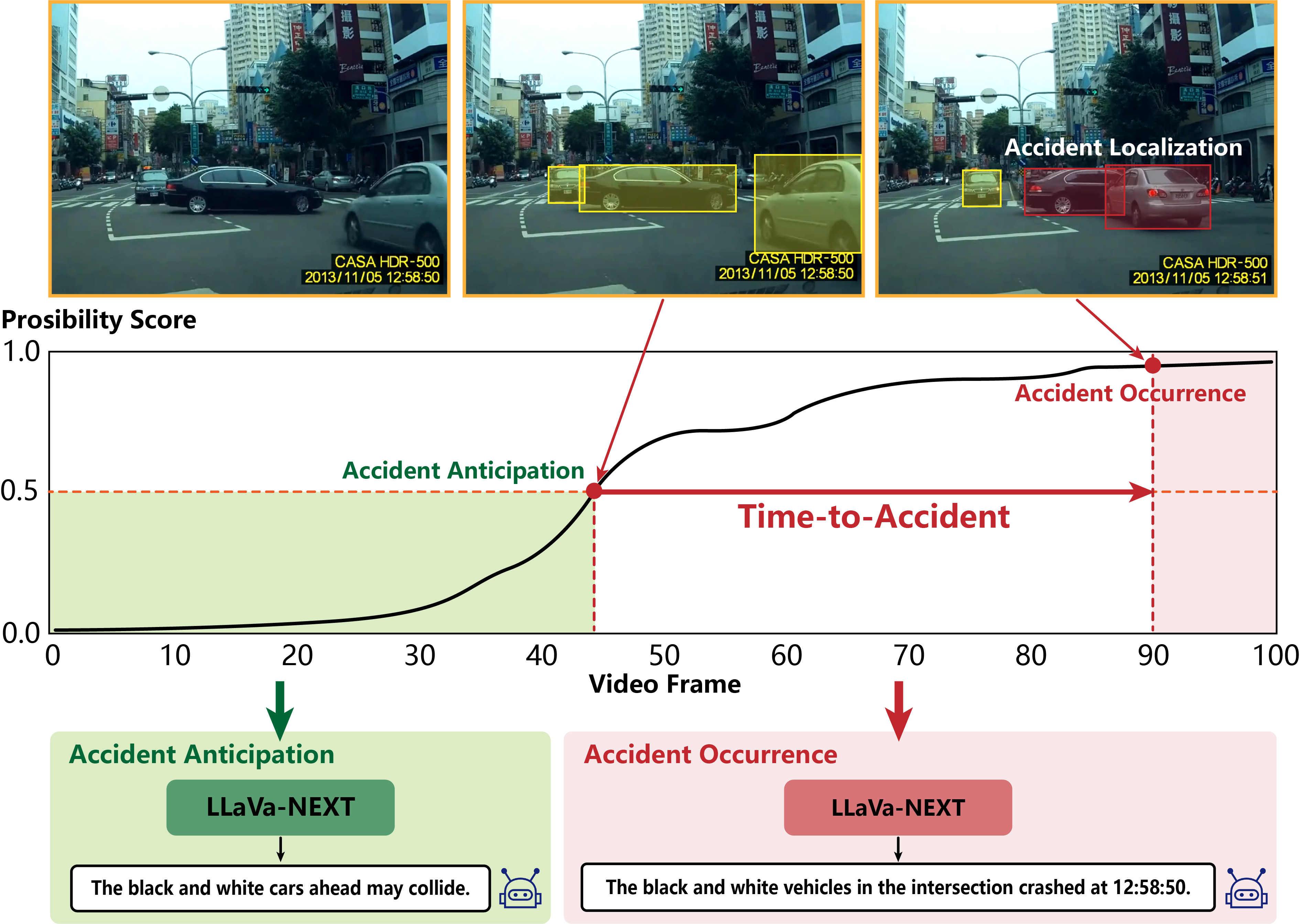
As autonomous driving systems increasingly become part of daily transportation, the ability to accurately anticipate and mitigate potential traffic accidents is paramount. Traditional accident anticipation models primarily utilizing dashcam videos are adept at predicting when an accident may occur but fall short in localizing the incident and identifying involved entities. Addressing this gap, this study introduces a novel framework that integrates Large Language Models (LLMs) to enhance predictive capabilities across multiple dimensions—what, when, and where accidents might occur. We develop an innovative chain-based attention mechanism that dynamically adjusts to prioritize high-risk elements within complex driving scenes. This mechanism is complemented by a three-stage model that processes outputs from smaller models into detailed multimodal inputs for LLMs, thus enabling a more nuanced understanding of traffic dynamics. Empirical validation on the DAD, CCD, and A3D datasets demonstrates superior performance in Average Precision (AP) and Mean Time-To-Accident (mTTA), establishing new benchmarks for accident prediction technology. Our approach not only advances the technological framework for autonomous driving safety but also enhances human-AI interaction, making predictive insights generated by autonomous systems more intuitive and actionable.

Overview of the Model Structure:
1. Three-Stage Framework: The model is structured into three primary stages:
2. Dynamic Attention Mechanisms: The model employs a novel chain-based attention mechanism termed dynamic diffuse attention that iteratively refines feature representations. Traditional attention mechanisms necessitate updating the attention matrix via gradient descent and backpropagation after processing a batch through the model. These approaches render the attention matrix heavily dependent on the overall model architecture and specific hyperparameters. To handle this problem, we pioneer the dynamic diffuse attention, which fine-tunes the granularity of the feature matrix across various iterations rather than in a batch-centric manner. This allows the system to prioritize high-risk objects in complex, multi-agent traffic scenes, enhancing both the accuracy and timeliness of accident predictions.

3. Multimodal Inputs: The model integrates various data types, including visual features from dashcam videos and object detection data, to create a comprehensive understanding of the driving environment. These multimodal inputs are essential for the model's ability to predict not just when an accident might occur, but also where and what might be involved.

We conduct extensive experiments on the DAD, CCD, and A3D datasets. Our model demonstrates superior performance in both AP and mTTA metrics. Notably, on the DAD dataset, our model achieved a remarkable 14.6% improvement in AP and a 16.4% increase in mTTA compared to the second-performing model. While enhancements on the CCD and A3D datasets were more modest, this can be attributed to the already near-optimal performance of competing models on these datasets. Additionally, our model secured the top scores across both AP and mTTA metrics.
Our analysis revealed that, unlike competing models which faced challenges in optimizing the trade-off between AP and mTTA, our model adeptly maintains this balance throughout the training process. While other models, such as DSTA, peaked in AP at the 20th epoch before experiencing a rapid decline, our model reaches peak performance by the 2nd epoch and maintains a minimal decline in performance thereafter, highlighting its rapid convergence and resilience to overfitting.
Furthermore, our model undergoes rigorous multi-class accuracy (AOLA) testing on the DAD dataset, achieving an accuracy rate of nearly 90%. This test involves classifying each video frame into one of 19 possible object categories, demonstrating the model's accuracy in recognizing and classifying a wide range of objects in complex traffic scenes. Achieving such a high accuracy rate, especially in a multi-class setting, underscores the effectiveness and adaptability of our model and sets a new benchmark in accident anticipation and localization for autonomous driving systems.