A Cognitive-Based Trajectory Prediction Approach for Autonomous Driving
Haicheng Liao*, Yongkang Li*, Zhenning Li†, Shengbo Eben Li, Senior Member, IEEE, and Chengzhong Xu†, Fellow, IEEE
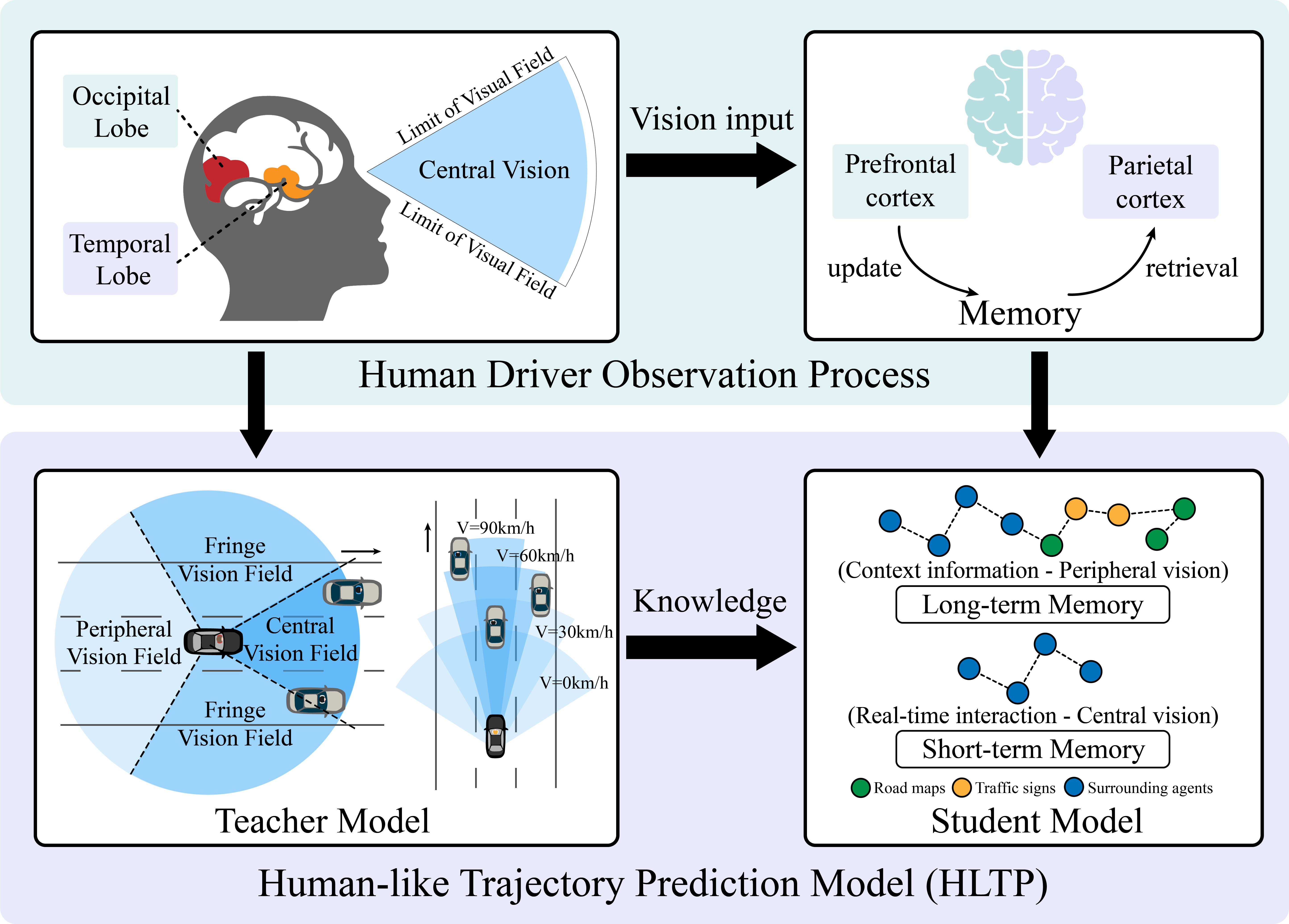
In autonomous vehicle (AV) technology, the ability to accurately predict the movements of surrounding vehicles is paramount for ensuring safety and operational efficiency. Incorporating human decision-making insights enables AVs to more effectively anticipate the potential actions of other vehicles, significantly improving prediction accuracy and responsiveness in dynamic environments. This paper introduces the Human-Like Trajectory Prediction (HLTP) model, which adopts a teacher-student knowledge distillation framework inspired by human cognitive processes. The HLTP model incorporates a sophisticated teacher-student knowledge distillation framework. The "teacher" model, equipped with an adaptive visual sector, mimics the visual processing of the human brain, particularly the functions of the occipital and temporal lobes. The "student" model focuses on real-time interaction and decision-making, drawing parallels to prefrontal and parietal cortex functions. This approach allows for dynamic adaptation to changing driving scenarios, capturing essential perceptual cues for accurate prediction. Evaluated using the Macao Connected and Autonomous Driving (MoCAD) dataset, along with the NGSIM and HighD benchmarks, HLTP demonstrates superior performance compared to existing models, particularly in challenging environments with incomplete data. The project page is available at Link.

Overview of the Model Structure:
1. Teacher-Student Knowledge Distillation Framework:
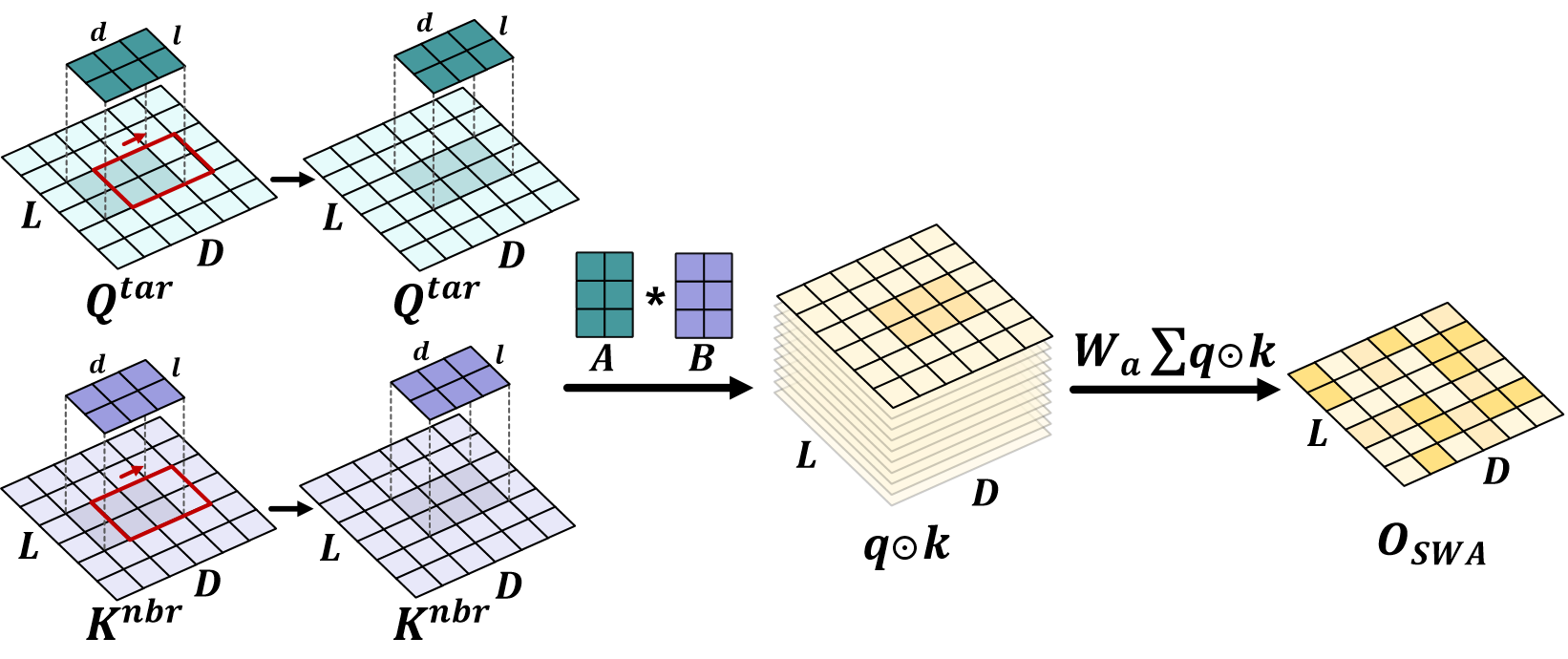
2. Shift-Window Attention Block (SWA): This component is designed to mimic the selective attention mechanism of the human brain. It operates by focusing on local visual fields, much like how human vision selectively focuses on certain areas. The SWA uses overlapping windows to ensure that the model captures detailed interaction between traffic participants.
3. Multimodal Decoder:The Multimodal Decoder integrates visual and contextual information from the surround-aware and teacher encoders. It uses a transformer framework to handle sequential data and a Gaussian Mixture Model (GMM) for probabilistic trajectory prediction. This approach allows the model to predict multiple possible future paths, considering different driving maneuvers, which enhances accuracy in dynamic traffic environments.
Our comprehensive evaluation demonstrates HLTP's superior performance compared to SOTA baselines. HLTP's ``student'' model, trained on only 1.5 seconds of recent trajectory data, surpasses the standard 3-second data reliance of baseline models. It notably achieves gains of 5.2% for short-term (2s) and 13.8% for long-term (5s) predictions on the NGSIM dataset. On the HighD dataset, all models, including HLTP, display fewer inaccuracies due to HighD's precise trajectories and larger data size. While short-term predictions are comparable across models, HLTP excels in long-term forecasting with a 41.6% RMSE improvement for up to 5 seconds. In complex right-hand-drive environments like urban streets and unstructured roads (MoCAD dataset), HLTP's accuracy gains range from 3.3% to 11.3%, underscoring its robustness and adaptability in diverse traffic scenarios.
In our benchmark against SOTA baselines, HLTP and HLTP (s) models demonstrate superior performance across all metrics, while maintaining a minimal parameter count. Despite limited access to many models' source codes, our analysis focuses on open-source options. Remarkably, HLTP (s) achieves high performance with significantly less complexity, reducing parameters by 71.41% and 55.89% compared to WSiP and CS-LSTM, respectively. Furthermore, HLTP (s) efficiently outperforms transformer-based STDAN and CF-LSTM, using 82.34% and 77.79% fewer parameters, respectively. This highlights the efficiency and adaptability of our lightweight ``teacher-student" knowledge distillation framework, offering practitioners a balance between accuracy and computational resource requirements.
Figure showcases the multimodal probabilistic prediction performance of HLTP on the NGSIM dataset, and the velocities of the target vehicle and its surrounding vehicles. The heat maps shown represent the Gaussian Mixture Model of predictions in challenging scenes. These visualizations show that the highest probability predictions of our model are very close to the ground truth, indicating its impressive performance. Additionally, it also visually demonstrates our model's ability to accurately predict complex scenarios such as merging and lane changing, confirming its effectiveness in various traffic situations.